| AP Statistics |
|
|
|
| Sections: 1.| Introduction 2.| Designing Samples 3.| Designing Experiments 4| Simulating Experiments |
|
|
|
Designing Samples A political scientist wants to know what percent of the voting-age population consider themselves conservatives. An automaker hires a market research firm to learn what percent of adults aged 18 to 35 recall seeing television advertise ment. for a new sport utility vehicle. Government economists inquire about average household income. In all these cases, we want to gather information about a large group of individuals. We will not, as in an experiment, impose a treatment in order to observe the response. Time, cost, and inconvenience forbid contacting every individual. In such cases, we gather information about only part of the group in order to draw conclusions about the whole.
POPULATION AND SAMPLE population. A sample is a part of the population that we actually examine in order to gather information.Notice that “population” is defined in terms of our desire for knowledge. If we wish to draw conclusions about all U.S. college students, that group is our population even if only local students are available for questioning. The sample is the part from which we draw conclusions about the whole. Sampling and conducting a census are two distinct ways of collecting data.
SAMPLING VERSUS A CENSUS involves studying a part in order to gain information about the whole. A census attempts to contact every individual in the entire population.We want information on current unemployment and public opinion next week, not next year. Moreover, a carefully conducted sample is often more accurate than a census. Accountants, for example, sample a firm’s inventory to verify the accuracy of the records. Attempting to count every last item in the warehouse would be not only expensive but inaccurate. Bored people do not count carefully. If conclusions based on a sample are to be valid for the entire population, a sound design for selecting the sample is required. The design of a sample refers to the method used to choose the sample from the population. Poor sample designs can produce misleading conclusions.
VOLUNTARY RESPONSE SAMPLE voluntary response sample consists of people who choose themselves by responding to a general appeal. Voluntary response samples are biased because people with strong opinions, especially negative opinions, are most likely to respond.
Example:
Polling opinion on the United Nations.
Voluntary response is one common type of bad sample design. Another is convenience sampling, which chooses the individuals easiest to reach. Here is an example of convenience sampling. Example:
Both voluntary response samples and convenience samples choose a sample that is almost guaranteed not to represent the entire population. These sampling methods display bias, or systematic error, in favoring some parts of the population over others.
BIAS biased if it systematically favors certain outcomes.
Simple random samples In a voluntary response sample, people choose whether to respond. In a convenience sample, the interviewer makes the choice. In both cases, personal choice produces bias. The statistician’s remedy is to allow impersonal chance to choose the sample. A sample chosen by chance allows neither favoritism by the sampler nor self-selection by respondents. Choosing a sample by chance attacks bias by giving all individuals an equal chance to be chosen. Rich and poor, young and old, black and white, all have the same chance to be in the sample. The simplest way to use chance to select a sample is to place names in a hat (the population) and draw out a handful (the sample). This is the idea of simple random sampling.
SIMPLE RANDOM SAMPLE
An SRS not only gives each individual an equal chance to be chosen (thus avoiding bias in the choice) but also gives every possible sample an equal chance to be chosen. There are other random sampling designs that give each individual, but not each sample, an equal chance. The idea of an SRS is to choose our sample by drawing names from a hat. In practice, computer software can choose an SRS almost instantly from a list of the individuals in the population. If you don’t use software, you can randomize by using a table of random numbers.
RANDOM NUMBERS
The Random Number Table is similar to asking an assistant (or a computer) to mix the digits 0 to 9 in a hat, draw one, then replace the digit drawn, mix again, draw a second digit, and so on. The assistant’s mixing and drawing save us the work of mixing and drawing when we need to randomize. The Random Number Table begins with the digits 39634 62349 74088 65564 16379 19713 To make the table easier to read, the digits appear in groups of five and in numbered rows. The groups and rows have no meaning— the table is just a long list of randomly chosen digits. Because the digits in the Random Number Table are random: Each entry is equally likely to be any of the 10 possibilities 0, 1, . . . , 9. • Each pair of entries is equally likely to be any of the 100 possible pairs 00, 01, . . . , 99.• Each triple of entries is equally likely to be any of the 1000 possibilities 000, 001, . . . , 999, and so on.These “equally likely” facts make it easy to use the Random Number Table to choose an SRS. Here is an example that shows how.
HOW TO CHOOSE AN SRS
Step 1: Label. Give each client a numerical label, using as few digits as possible. Two digits are needed to label 30 clients, so we use labels 01, 02, 03, . . . , 29, 30. It is also correct to use labels 00 to 29 or even another choice of 30 two-digit labels.Here is the list of clients, with labels attached:
Step 2: Table. Enter the Random Number Table anywhere and read two-digit groups. Suppose we enter at line 30, which is72249 04037 36192 40221 14918 53437 60571 40995 55006 10694 The first 10 two-digit groups in this line are 72 24 90 40 37 36 19 24 02 21 Each successive two-digit group is a label. The labels 00 and 31 to 99 are not used in this example, so we ignore them. The first 5 labels between 01 and 30 that we encounter in the table choose our sample. Of the first 10 labels in line 30, we ignore 5 because they are too high (over 30). The others are 24, 19, 24, 02, and 21. The clients labeled 02, 19, 21 and 24 go into the sample. Ignore the second 24 because that client is already in the sample. Now run your finger across line 30 (and continue to line 31 if needed) until 5 clients are chosen. The sample is the clients labeled 02, 14, 19, 21, and 24. These are Accent Printing, Fleisch Realty, Liu’s Chinese Restaurant, Peerless Machine, and Riverside Tavern.
CHOOSING AN SRS
You can assign labels in any convenient manner, such as alphabetical order for names of people. Be certain that all labels have the same number of digits. Only then will all individuals have the same chance to be chosen. Use the shortest possible labels: one digit for a population of up to 10 members, 2 digits for 11 to 100 members, three digits for 101 to 1000 members, and so on. As standard practice, we recommend that you begin with label 1 (or 01 or 001, as needed). You can read digits from the Random Number Table in any order—across a row, down a column, and so on—because the table has no order. As standard practice, we recommend reading across rows. Other sampling designs The general framework for designs that use chance to choose a sample is a probability sample.
PROBABILITY SAMPLE
Some probability sampling designs (such as an SRS) give each member of the population an equal chance to be selected. This may not be true in more elaborate sampling designs. In every case, however, the use of chance to select the sample is the essential principle of statistical sampling. Designs for sampling from large populations spread out over a wide area are usually more complex than an SRS. For example, it is common to sample important groups within the population separately, then combine these samples. This is the idea of a stratified sample.
STRATIFIED RANDOM SAMPLE
Choose the strata based on facts known before the sample is taken. For example, a population of election districts might be divided into urban, suburban, and rural strata. A stratified design can produce more exact information than an SRS of the same size by taking advantage of the fact that individuals in the same stratum are similar to one another. If all individuals in each stratum are identical, for example, just one individual from each stratum is enough to completely describe the population. Example
WHO WROTE THAT SONG?
Another common means of restricting random selection is to choose the sample in stages. This is usual practice for national samples of households or people. For example, data on employment and unemployment are gathered by the government’s Current Population Survey, which conducts interviews in about 55,000 households each month. It is not practical to maintain a list of all U.S. households from which to select an SRS. Moreover, the cost of sending interviewers to the widely scattered households in an SRS would be too high. The Current Population Survey therefore uses a multistage sampling design. The final sample consists of clusters of near-by households that an interviewer can easily visit. Most opinion polls and other national samples are also multistage, though interviewing in most national samples today is done by telephone rather than in person, eliminating the economic need for clustering. The Current Population Survey sampling design is roughly as follows: Divide the United States into 2007 geographical areas called Primary Sampling Units, or PSUs. Select a sample of 756 PSUs. This sample includes the 428 PSUs with the largest population and a stratified sample of 328 of the others. Stage 2: Divide each PSU selected into smaller areas called “neighborhoods.” Stratify the neighborhoods using ethnic and other information and take a stratified sample of the neighborhoods in each PSU.Stage 3: Sort the housing units in each neighborhood into clusters of four nearby units. Interview the households in a random sample of these clusters.Analysis of data from sampling designs more complex than an SRS takes us beyond basic statistics. But the SRS is the building block of more elaborate designs, and analysis of other designs differs more in complexity of detail than in fundamental concepts.Try Self Check 22 Proceed to Statistics Assignment 10: Working with the Random Number Table Cautions about sample surveys Random selection eliminates bias in the choice of a sample from a list of the population. When the population consists of human beings, however, accurate information from a sample requires much more than a good sampling design. To begin, we need an accurate and complete list of the population. Because such a list is rarely available, most samples suffer from some degree of undercoverage. A sample survey of households, for example, will miss not only homeless people but prison inmates and students in dormitories. An opinion poll conducted by telephone will miss the 7% to 8% of American households without residential phones. The results of national sample surveys therefore have some bias if the people not covered—who most often are poor people—differ from the rest of the population.A more serious source of bias in most sample surveys is nonresponse, which occurs when a selected individual cannot be contacted or refuses to cooperate. Nonresponse to sample surveys often reaches 30% or more, even with careful planning and several callbacks. Because nonresponse is higher in urban areas, most sample surveys substitute other people in the same area to avoid favoring rural areas in the final sample. If the people contacted differ from those who are rarely at home or who refuse to answer questions, some bias remains.
UNDERCOVERAGE AND NONRESPONSE occurs when some groups in the population are left out of the process of choosing the sample. Nonresponse occurs when an individual chosen for the sample can’t be contacted or does not cooperate.Example:
THE CENSUS UNDERCOUNT
For the 2000 census, the Bureau planned to replace follow-up of all nonresponders with more intense pursuit of a probability sample of nonresponding households plus a national sample of 750,000 households. The final counts would be based on comparing the national sample with the original responses. This idea was politically controversial. The Supreme Court ruled that the sampling could be used for most purposes, but not for dividing seats in Congress among the states.
In addition, the behavior of the respondent or of the interviewer can cause response bias in sample results. Respondents may lie, especially if asked about illegal or unpopular behavior. The sample then underestimates the presence of such behavior in the population. An interviewer whose attitude suggests that some answers are more desirable than others will get these answers more often. The race or sex of the interviewer can influence responses to questions about race relations or attitudes toward feminism. Answers to questions that ask respondents to recall past events are often inaccurate because of faulty memory. For example, many people “telescope” events in the past, bringing them forward in memory to more recent time periods. “Have you visited a dentist in the last 6 months?” will often draw a “Yes” from someone who last visited a dentist 8 months ago. Careful training of interviewers and careful supervision to avoid variation among the interviewers can greatly reduce response bias. Good interviewing technique is another aspect of a well-done sample survey.The wording of questions is the most important influence on the answers given to a sample survey. Confusing or leading questions can introduce strong bias, and even minor changes in wording can change a survey’s outcome. Here are two examples.
SHOULD WE BAN DISPOSABLE DIAPERS?
It is estimated that disposable diapers account for less than 2% of the trash in today’s landfills. In contrast, beverage containers, third-class mail and yard wastes are estimated to account for about 21% of the trash in landfills. Given this, in your opinion, would it be fair to ban disposable diapers? This question gives information on only one side of an issue, then asks an opinion. That’s a sure way to bias the responses. A different question that described how long disposable diapers take to decay and how many tons they contribute to landfills each year would draw a quite different response.
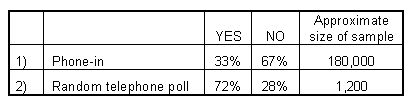
DOUBTING THE HOLOCAUST
Never trust the results of a sample survey until you have read the exact questions posed. The sampling design, the amount of nonresponse, and the date of the survey are also important. Good statistical design is a part, but only a part, of a trustworthy survey. Inference about the population Despite the many practical difficulties in carrying out a sample survey, using chance to choose a sample does eliminate bias in the actual selection of the sample from the list of available individuals. But it is unlikely that results from a sample are exactly the same as for the entire population. Sample results, like the official unemployment rate obtained from the monthly Current Population Survey, are only estimates of the truth about the population. If we select two samples at random from the same population, we will draw different individuals. So the sample results will almost certainly differ somewhat. Two runs of the Current Population Survey would produce somewhat different unemployment rates. Properly designed samples avoid systematic bias, but their results are rarely exactly correct and they vary from sample to sample. How accurate is a sample result like the monthly unemployment rate? We can’t say for sure, because the result would be different if we took another sample. But the results of random sampling don’t change haphazardly from sample to sample. Because we deliberately use chance, the results obey the laws of probability that govern chance behavior. We can say how large an error we are likely to make in drawing conclusions about the population from a sample. Results from a sample survey usually come with a margin of error that sets bounds on the size of the likely error. How to do this is part of the business of statistical inference. One point is worth making now: larger random samples give more accurate results than smaller samples. By taking a very large sample, you can be confident that the sample result is very close to the truth about the population. The Current Population Survey’s sample of 50,000 households estimates the national unemployment rate very accurately. Of course, only probability samples carry this guarantee. Nightline’s voluntary response sample is worthless even though 186,000 people called in. Using a probability sampling design and taking care to deal with practical difficulties reduce bias in a sample. The size of the sample then determines how close to the population truth the sample result is likely to fall. Wow! This lesson introduced you to a lot of new terms. The terms are very important as we continue on our journey. Try Self-Check 23 Multiple Choice 9 |