| AP Statistics |
|
|
|
| Sections: 1.| Introduction 2| Designing Samples 3| Designing Experiments 4| Simulating Experiments |
|
|
|
Designing Experiments A study is an experiment when we actually do something to people, animals, or objects in order to observe the response. Here is the basic vocabulary of experiments. EXPERIMENTAL UNITS, SUBJECTS, TREATMENT experimental units. When the units are human beings, they are called subjects. A specific experimental condition applied to the units is called a treatment. Because the purpose of an experiment is to reveal the response of one variable to changes in other variables, the distinction between explanatory and response variables is important. The explanatory variables in an experiment are often called factors. Many experiments study the joint effects of several factors. In such an experiment, each treatment is formed by combining a specific value (often called a level) of each of the factors. Example:
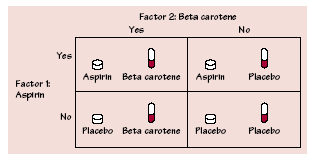
THE PHYSICIANS� HEALTH STUDY subjects were 21,996 male physicians. There were two factors, each having two levels: aspirin (yes or no) and beta carotene (yes or no). Combinations of the levels of these factors form the four treatments shown in the figure below . One-fourth of the subjects were assigned to each of these treatments.
placebo, a dummy pill that looked and tasted like the aspirin but had no active ingredient. On even-numbered days, they took a red capsule containing either beta carotene or a placebo. There were several response variables---the study looked for heart attacks, several kinds of cancer, and other medical outcomes. After several years, 239 of the placebo group but only 139 of the aspirin group had suffered heart attacks. This difference is large enough to give good evidence that taking aspirin does reduce heart attacks. It did not appear, however, that beta carotene had any effect.
Example:
The two examples above illustrate the big advantage of experiments over observational studies. In principle, experiments can give good evidence for causation. All the doctors in the Physicians� Health Study took a pill every other day, and all got the same schedule of checkups and information. The only difference was the content of the pill. When one group had many fewer heart attacks, we conclude that it was the content of the pill that made the difference. Julie�s observational study�a census of all seniors in her high school�does a good job of describing differences between seniors who have studied foreign languages and those who have not. But she can say nothing about cause and effect.Another advantage of experiments is that they allow us to study the specific factors we are interested in, while controlling the effects of lurking variables. The subjects in the Physicians� Health Study were all middle-aged male doctors and all followed the same schedule of medical checkups. These similarities reduce variation among the subjects and make any effects of aspirin or beta carotene easier to see. Experiments also allow us to study the combined effects of several factors. The interaction of several factors can produce effects that could not be predicted from looking at the effects of each factor alone. The Physicians� Health Study tells us that aspirin helps prevent heart attacks, at least in middle-aged men, and that beta carotene taken with the aspirin neither helps nor hinders aspirin�s protective powers. Comparative experiments Laboratory experiments in science and engineering often have a simple design with only a single treatment, which is applied to all of the experimental units. The design of such an experiment can be outlined as
For example, we may subject a beam to a load (treatment) and measure its deflection (observation). We rely on the controlled environment of the laboratory to protect us from lurking variables. When experiments are conducted in the field or with living subjects, such simple designs often yield invalid data. That is, we cannot tell whether the response was due to the treatment or to lurking variables. Another medical example will show what can go wrong. Example: TREATING ULCERS Journal of the American Medical Association showed that gastric freezing did reduce acid production and relieve ulcer pain. The treatment was safe and easy and was widely used for several years. The design of the experiment was
The gastric freezing experiment was poorly designed. The patients� response may have been due to the placebo effect. A placebo is a dummy treatment. Many patients respond favorably to any treatment, even a placebo. This may be due to trust in the doctor and expectations of a cure, or simply to the fact that medical conditions often improve without treatment. The response to a dummy treatment is the placebo effect. A later experiment divided ulcer patients into two groups. One group was treated by gastric freezing as before. The other group received a placebo treatment in which the liquid in the balloon was at body temperature rather than freezing. The results: 34% of the 82 patients in the treatment group improved, but so did 38% of the 78 patients in the placebo group. This and other properly designed experiments showed that gastric freezing was no better than a placebo, and its use was abandoned.
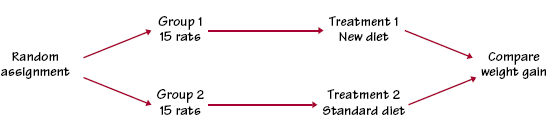
The first gastric freezing experiment gave misleading results because the effects of the explanatory variable were confounded with (mixed up with) the placebo effect. We can defeat confounding by comparing two groups of patients, as in the second gastric freezing experiment. The placebo effect and other lurking variables now operate on both groups. The only difference between the groups is the actual effect of gastric freezing. The group of patients who received a sham treatment is called a control group, because it enables us to control the effects of outside variables on the outcome. Control is the first basic principle of statistical design of experiments. Comparison of several treatments in the same environment is the simplest form of control. Without control, experimental results in medicine and the behavioral sciences can be dominated by such influences as the details of the experimental arrangement, the selection of subjects, and the placebo effect. The result is often bias, systematic favoritism toward one outcome. An uncontrolled study of a new medical therapy, for example, is biased in favor of finding the treatment effective because of the placebo effect. It should not surprise you to learn that uncontrolled studies in medicine give new therapies a much higher success rate than proper comparative experiments. Well-designed experiments, like the Physicians� Health Study and the second gastric freezing study, usually compare several treatments.Try Self-Check 24 Randomization The design of an experiment first describes the response variable or variables, the factors (explanatory variables), and the layout of the treatments, with comparison as the leading principle. The figure above illustrates this aspect of the design of the Physicians� Health Study. The second aspect of design is the rule used to assign the experimental units to the treatments. Comparison of the effects of several treatments is valid only when all treatments are applied to similar groups of experimental units. If one corn variety is planted on more fertile ground, or if one cancer drug is given to more seriously ill patients, comparisons among treatments are meaningless. Systematic differences among the groups of experimental units in a comparative experiment cause bias. How can we assign experimental units to treatments in a way that is fair to all of the treatments?Experimenters often attempt to match groups by elaborate balancing acts. Medical researchers, for example, try to match the patients in a �new drug� experimental group and a �standard drug� control group by age, sex, physical condition, smoker or not, and so on. Matching is helpful but not adequate� there are too many lurking variables that might affect the outcome. The experimenter is unable to measure some of these variables and will not think of others until after the experiment. Some important variables, such as how advanced a cancer patient�s disease is, are so subjective that an experimenter might bias the study by, for example, assigning more advanced cancer cases to a promising new treatment in the unconscious hope that it will help them. The statistician�s remedy is to rely on chance to make an assignment that does not depend on any characteristic of the experimental units and that does not rely on the judgment of the experimenter in any way. The use of chance can be combined with matching, but the simplest design creates groups by chance alone. Here is an example. TESTING A BREAKFAST FOOD each group is an SRS of the available rats. The figure below outlines the design of this experiment.
We can use software or the table of random digits to randomize. Label the rats 01 to 30. Enter the Random Number Table at line 30. Run your finger along this line (and continue to lines 31 and 32 as needed) until 15 rats are chosen. They are the rats labeled 24, 19, 02, 21, 14, 09, 06, 05, 04, 15, 29, 17, 07, 28, and 20. These rats form the experimental group; the remaining 15 are the control group.
Randomization, the use of chance to divide experimental units into groups, is an essential ingredient for a good experimental design. The design above combines comparison and randomization to arrive at the simplest randomized comparative design. This �flowchart� outline presents all the essentials: randomization, the sizes of the groups and which treatment they receive, and the response variable. There are, as we will see later, statistical reasons for generally using treatment groups about equal in size. Randomized comparative experiments The logic behind the randomized comparative design above is as follows: Randomization produces groups of rats that should be similar in all respects before the treatments are applied. � Comparative design ensures that influences other than the diets operate equally on both groups.� Therefore, differences in average weight gain must be due either to the diets or to the play of chance in the random assignment of rats to the two diets.That �either-or� deserves more thought. We cannot say that any difference in the average weight gains of rats fed the two diets must be caused by a difference between the diets. There would be some difference even if both groups received the same diet, because the natural variability among rats means that some grow faster than others. Chance assigns the faster-growing rats to one group or the other, and this creates a chance difference between the groups. We would not trust an experiment with just one rat in each group, for example. The results would depend too much on which group got lucky and received the faster-growing rat. If we assign many rats to each diet, however, the effects of chance will average out and there will be little difference in the average weight gains in the two groups unless the diets themselves cause a difference. �Use enough experimental units to reduce chance variation� is the third big idea of statistical design of experiments.PRINCIPLES OF EXPERIMENTAL DESIGN
We hope to see a difference in the responses so large that it is unlikely to happen just because of chance variation. We can use the laws of probability, which give a mathematical description of chance behavior, to learn if the treatment effects are larger than we would expect to see if only chance were operating. If they are, we call them statistically significant. STATISTICAL SIGNIFICANCE
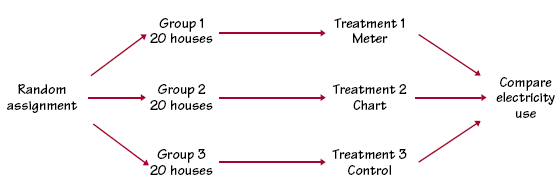
You will often see the phrase �statistically significant� in reports of investigations in many fields of study. It tells you that the investigators found good evidence for the effect they were seeking. The Physicians� Health Study, for example, reported statistically significant evidence that aspirin reduces the number of heart attacks compared with a placebo. Example: ENCOURAGING ENERGY CONSERVATION
When all experimental units are allocated at random among all treatments, the experimental design is completely randomized. Completely randomized designs can compare any number of treatments. In the example, Encouraging Energy Conservation, we compared the three levels of a single factor: the method used to encourage energy conservation. The treatments can be formed by more than one factor. The Physicians� Health Study had two factors, which combine to form the four treatments. The study used a completely randomized design that assigned 5499 of the 21,996 subjects to each of the four treatments.Try Self-Check 25 Cautions about experimentation The logic of a randomized comparative experiment depends on our ability to treat all the experimental units identically in every way except for the actual treatments being compared. Good experiments therefore require careful attention to details. For example, the subjects in both the Physicians� Health Study and the second gastric freezing experiment all got the same medical attention over the several years the studies continued. Moreover, these studies were double-blind�neither the subjects themselves nor the medical personnel who worked with them knew which treatment any subject had received. The double-blind method avoids unconscious bias by, for example, a doctor who doesn�t think that �just a placebo�� can benefit a patient. DOUBLE-BLIND EXPERIMENT
The most serious potential weakness of experiments is lack of realism. The subjects or treatments or setting of an experiment may not realistically duplicate the conditions we really want to study. Here are some examples.RESPONSE TO ADVERTISING
CENTER BRAKE LIGHTS
Lack of realism can limit our ability to apply the conclusions of an experiment to the settings of greatest interest. Most experimenters want to generalize their conclusions to some setting wider than that of the actual experiment. Statistical analysis of the original experiment cannot tell us how far the results will generalize. Nonetheless, the randomized comparative experiment, because of its ability to give convincing evidence for causation, is one of the most important ideas in statistics. Matched pairs designs Completely randomized designs are the simplest statistical designs for experiments. They illustrate clearly the principles of control, randomization, and replication. However, completely randomized designs are often inferior to more elaborate statistical designs. In particular, matching the subjects in various ways can produce more precise results than simple randomization. Example:
CEREAL LEAF BEETLES matched pairs design in which we mount boards of both colors on each pole. The observations (numbers of beetles trapped) are matched in pairs from the same poles. We compare the number of trapped beetles on a yellow board with the number trapped by the green board on the same pole. Because the boards are mounted one above the other, we select the color of the top board at random. Just toss a coin for each board---if the coin falls heads, the yellow board is mounted above the green board.
Matched pairs designs compare just two treatments. We choose blocks of two units that are as closely matched as possible. In the Cereal Leaf Beetles example, two boards on the same pole form a block. We assign one of the treatments to each unit by tossing a coin or reading odd and even digits from the Random Number Table. Alternatively, each block in a matched pairs design may consist of just one subject, who gets both treatments one after the other. Each subject serves as his or her own control. The order of the treatments can influence the subject�s response, so we randomize the order for each subject, again by a coin toss. Block designs The matched pairs design of the Cereal Leaf Beetles example uses the principles of comparison of treatments, randomization, and replication on several experimental units. However, the randomization is not complete (all locations randomly assigned to treatment groups) but restricted to assigning the order of the boards at each location. The matched pairs design reduces the effect of variation among locations in the field by comparing the pair of boards at each location. Matched pairs are an example of block designs. BLOCK DESIGN
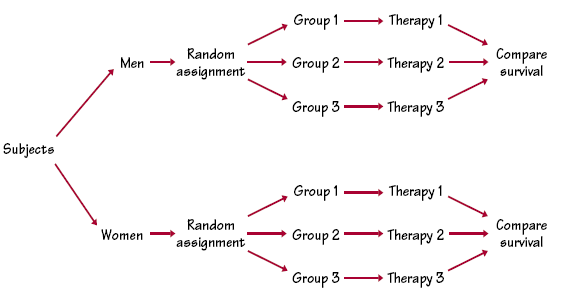
Block designs can have blocks of any size. A block design combines the idea of creating equivalent treatment groups by matching with the principle of forming treatment groups at random. Blocks are another form of control. They control the effects of some outside variables by bringing those variables into the experiment to form the blocks. Here are some typical examples of block designs.COMPARING CANCER THERAPIES
SOYBEANS
STUDYING WELFARE SYSTEMS
Blocks allow us to draw separate conclusions about each block, for example, about men and women in the cancer study. Blocking also allows more precise overall conclusions, because the systematic differences between men and women can be removed when we study the overall effects of the three therapies. The idea of blocking is an important additional principle of statistical design of experiments. A wise experimenter will form blocks based on the most important unavoidable sources of variability among the experimental units. Randomization will then average out the effects of the remaining variation and allow an unbiased comparison of the treatments. Try Self-Check 26 Proceed to Statistics Assignment 11: Experimental Design |