| AP Statistics |
|
|
|
| Sections: 1.| Transforming Relationships 2.| Cautions about Correlation and Regression 3| Relations in Categorical Data |
|
|
|
Cautions about Correlation and Regression Correlation and regression are powerful tools for describing the relationship between two variables. When you use these tools, you must be aware of their limitations, beginning with the fact that correlation and regression describe only linear relationships. Also remember that the correlation r and the least-squares regression line are not resistant. One influential observation or incorrectly entered data point can greatly change these measures. Always plot your data before interpreting regression or correlation. Here are some other cautions to keep in mind when you apply correlation and regression or read accounts of their use.Interpolation and ExtrapolationWe will consider interpolation and extrapolation as applied to bivariate data; that is, data involving two variables. When two variables are measured that describe the same object or individual, one of them is usually identified as the explanatory variable and the other as the response variable. If the data was produced in an experiment, the explanatory variable is the factor that was manipulated by the experimenter, while the values of the response variable are paired with (and possibly caused by) the parameter described by the explanatory variable. If no variables are manipulated, the explanatory and response variables will be designated in such a way as to preserve the proper causal relationship between them if possible, though it may sometimes be a mistake to assume that one is caused by the other. Example: Suppose that a consumer group purchased various kinds of chocolate candies. Each chocolate was rated on a scale of 1 to 10 according to the taste. The cost per ounce for each different type was also recorded. The following table was constructed using the rating and the cost per ounce.
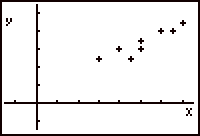
In this example we will designate cost as the explanatory variable, since it seems reasonable to suppose that expensive chocolate will taste better, though one can see the difficulties involved when making assumptions about causality. For instance, might it not be more accurate to say that the cost and the taste are both caused by the quality of the ingredients? In another famous example, one can consider the relationship between shoe size and reading ability for children in grades K-4. There is certainly a relationship between the two variables, with better readers generally having larger shoe sizes. But you might not want to conclude that large feet cause reading aptitude. A scatterplot of the data may assist in determining some relationship among the data, if any exists. If the data appears to have some relationship, a mathematical model can be used to make predictions about cost and rating. Note that in a scatterplot, the explanatory variable is generally graphed on the x-axis. Here are the scatterplots:
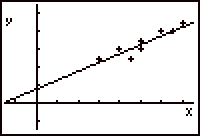
Scatterplot of the data Linear model for the data The tick marks on each set of axes are two units apart. The x-axis represents the cost per ounce and the y-axis represents the rating. The points in the scatterplot appear to follow a fairly linear trend. The relationship among the data can therefore be modeled by a linear function. Any line which appears to fit the data could be used as a model, but in this case the linear model is the statistically-defined line of best fit. This "best-fit" line was generated by software that uses a statistical analysis technique, though it is visually apparent that the line follows the trend of the data fairly well. The equation of the line is y = 0.5x + 1.5, or rating = 0.5 (cost) + 1.5. A general observation about the graph would be that the greater the cost of the chocolate, the better the rating. Since our best-fit line is a reasonably suitable model for the data, we can use it to make predictions about the explanatory and response variables. When we make predictions using our model, we don't care about thorny causality issues. We are merely following the trend that is present in the data, whatever the actual cause. What rating would a 11ó chocolate have? From the equation of the model, y = 0.5(11) + 1.5 = 7. Thus, we would predict that a chocolate costing 11ó per ounce would have a rating of 7. This prediction is called an interpolation. Interpolation Any prediction made between known values of data is called interpolation. What would be the cost of a chocolate that received a rating of 3? Substituting a value of 3 into the rating variable in our equation we get 3 = 0.5x + 1.5, so 0.5 x = 1.5 and x = 3 cents. This seems to be a reasonable prediction. However, it could be a questionable conclusion. We have extended the prediction beyond the domain of the data. In this case 3 is not between the lower and upper bound of the cost, for which we have only collected data between 6ó and 14ó. What is the rating for a chocolate costing 18ó per ounce? We get y = 0.5 (18) + 1.5, so y = 10.5. We now estimate a rating of 10.5, which is beyond the rating scale. In fact, any cost over 17ó per ounce yields a value that is not on the rating scale. A prediction made beyond the known values of data is called extrapolation.
Basing predictions upon extrapolation is often more risky than interpolation, because it depends on the assumption that a pattern will continue past the range of the known data. As shown above, our model cannot possibly hold for values of x greater than 17. One must use caution when making predictions through extrapolation. In this example, we considered data that followed a linear trend. Some phenomena are modeled more effectively with more complicated functions. There are statistical analysis techniques that can be used to generate a multitude of modeling functions, including quadratic, polynomial, exponential and logarithmic functions. Lurking Variables A variable that has a very important effect on the relationship of the variables under study, but is not one of the variables being studied is called a lurking variable. One could safely conclude that there is a negative linear association between car engine size (measured in cubic inches or Liters) and miles per gallon (mpg). The smaller the engine, the higher the mpg and vice versa. Manufacturers place stickers on new car windows indicating the estimated city and road mpg. You and your neighbor buy the same exact model and after several months you compare mpg. You tell your neighbor that you are averaging about 25 miles per gallon. He is surprised by the number, he averages 19 mpg. What could be going on here? You do notice that your neighbor driving habits are different than yours. He is constantly "racing" the motor, drives fast, and "stomps" the pedal to accelerate. Your driving habits are more conservative. Your neighbor thinks that the correlation between engine size and mpg is not true. If he is only getting 19 mpg then he should have a bigger engine. This is an example of a lurking variable affecting fuel economy (mpg). A variable not usually considered is the way the operator drives the car. The driver and his style of driving loiters in the background and varies the fuel economy. The Question of Causation In many studies of the relationship between two variables, the goal is to establish that changes in the explanatory variable cause changes in the response variable. Even when a strong association is present, the conclusion that this association is due to a causal link between the variables is often elusive. What ties between two variables (and others lurking in the background) can explain an observed association? What constitutes good evidence for causation? We begin our consideration of these questions with a set of examples. In each case, there is a clear association between an explanatory variable x and a response variable y. Moreover, the association is positive whenever the direction makes sense.
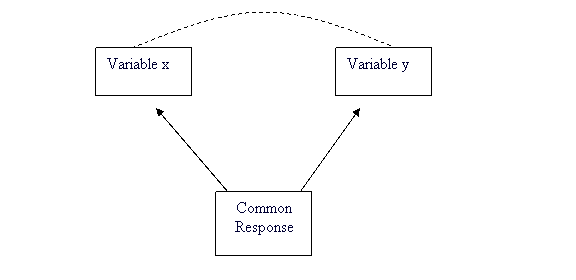
Items 1 and 2 above are examples of direct causation. Thinking about these examples, however, shows that ôcausationö is not a simple idea. A study of Mexican American girls aged 9 to 12 years recorded body mass index (BMI), a measure of weight relative to height, for both the girls and their mothers. People with high BMI are overweight or obese. The study also measured hours of television, minutes of physical activity, and intake of several kinds of food. The strongest correlation (r = 0.506) was between the BMI of daughters and the BMI of their mothers. Body type is in part determined by heredity. Daughters inherit half their genes from their mothers. There is therefore a direct causal link between the BMI of mothers and daughters. Yet the mothersĺ BMIs explain only 25.6% (thatĺs r2 ) of the variation among the daughtersĺ BMIs. Other factors, such as diet and exercise, also influence BMI. Even when direct causation is present, it is rarely a complete explanation of an association between two variables. 2. The best evidence for causation comes from experiments that actually change x while holding all other factors fixed. If y changes, we have good reason to think that x caused the change in y. Experiments show conclusively that large amounts of saccharin in the diet cause bladder tumors in rats. Should we avoid saccharin as a replacement for sugar in food? Rats are not people. Although we canĺt experiment with people, studies of people who consume different amounts of saccharin show little association between saccharin and bladder tumors. Even well-established causal relations may not generalize to other settings.Explaining Association: Common Response ôBeware the lurking variableö is good advice when thinking about an association between two variables. The diagram below illustrates common response. The observed association between the variables x and y is explained by a lurking variable z. Both x and y change in response to changes in z. This common response creates an association even though there may be no direct causal link between x and y.
The third and fourth items in the example above illustrate how common response can create an association.
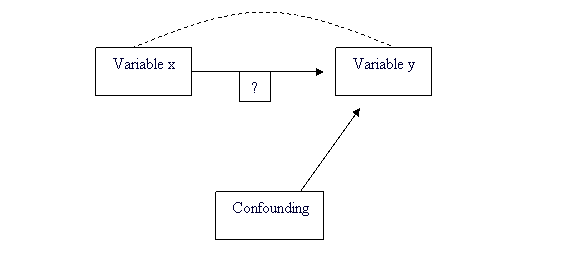
Explaining Association: Confounding As noted in the example with Mexican American girls inheritance no doubt explains part of the association between the body mass indexes (BMIs) of daughters and their mothers. Can we use r or r2 to say how much inheritance contributes to the daughtersĺ BMIs? No. It may well be that mothers who are overweight also set an example of little exercise, poor eating habits, and lots of television. Their daughters pick up these habits to some extent, so the influence of heredity is mixed up with influences from the girlsĺ environment. We call this mixing of influences confounding.CONFOUNDING confounded when their effects on a response variable cannot be distinguished from each other. The confounded variables may be either explanatory variables or lurking variables. When many variables interact with each other, confounding of several variables often prevents us from drawing conclusions about causation. The diagram below illustrates confounding. Both the explanatory variable x and the lurking variable z may influence the response variable y. Because x is confounded with z, we cannot distinguish the influence of x from the influence of z. We cannot say how strong the direct effect of x on y is. In fact, it can be hard to say if x influences y at all.
The last two associations in the example above (Items 5 and 6) are explained in part by confounding. Many studies have found that people who are active in their religion live longer than nonreligious people. But people who attend church or mosque or synagogue also take better care of themselves than non-attendees. They are less likely to smoke, more likely to exercise, and less likely to be overweight. The effects of these good habits are confounded with the direct effects of attending religious services. 6. It is likely that more education is a cause of higher incomeŚmany highly paid professions require advanced education. However, confounding is also present. People who have high ability and come from prosperous homes are more likely to get many years of education than people who are less able or poorer. Of course, people who start out able and rich are more likely to have high earnings even without much education. We canĺt say how much of the higher income of well-educated people is actually caused by their education.Many observed associations are at least partly explained by lurking variables. Both common response and confounding involve the influence of a lurking variable (or variables) z on the response variable y. The distinction between these two types of relationships is less important than the common element, the influence of lurking variables. The most important lesson of these examples is one we have already emphasized: even a very strong association between two variables is not by itself good evidence that there is a cause-and-effect link between the variables. Establishing Causation How can a direct causal link between x and y be established? The best methodŚindeed, the only fully compelling methodŚof establishing causation is to conduct a carefully designed experiment in which the effects of possible lurking variables are controlled. Much of Unit 5 is devoted to the art of designing convincing experiments. Many of the sharpest disputes in which statistics plays a role involve questions of causation that cannot be settled by experiment. Does gun control reduce violent crime? Does living near power lines cause cancer? Has increased free trade helped to increase the gap between the incomes of more educated and less educated American workers? All of these questions have become public issues. All concern associations among variables. And all have this in common: they try to pinpoint cause and effect in a setting involving complex relations among many interacting variables. Common response and confounding, along with the number of potential lurking variables, make observed associations misleading. Experiments are not possible for ethical or practical reasons. We canĺt assign some people to live near power lines or compare the same nation with and without free-trade agreements. Example: DO POWER LINES INCREASE THE RISK OF LEUKEMIA?
ôNo evidenceö that magnetic fields are connected with childhood leukemia doesnĺt prove that there is no risk. It says only that a careful study could not find any risk that stands out from the play of chance that distributes leukemia cases across the landscape. Critics continue to argue that the study failed to measure some lurking variables, or that the children studied donĺt fairly represent all children. Nonetheless, a carefully designed study comparing children with and without leukemia is a great advance over haphazard and sometimes emotional counting of cancer cases. Example: DOES SMOKING CAUSE LUNG CANCER?
Letĺs answer this question in general terms: What are the criteria for establishing causation when we cannot do an experiment? The association is strong. The association between smoking and lung cancer is very strong. Ľ The association is consistent. Many studies of different kinds of people in many countries link smoking to lung cancer. That reduces the chance that a lurking variable specific to one group or one study explains the association.Ľ Higher doses are associated with stronger responses. People who smoke more cigarettes per day or who smoke over a longer period get lung cancer more often. People who stop smoking reduce their risk.Ľ The alleged cause precedes the effect in time. Lung cancer develops after years of smoking. The number of men dying of lung cancer rose as smoking became more common, with a lag of about 30 years. Lung cancer kills more men than any other form of cancer. Lung cancer was rare among women until women began to smoke. Lung cancer in women rose along with smoking, again with a lag of about 30 years, and has now passed breast cancer as the leading cause of cancer death among women.Ľ The alleged cause is plausible. Experiments with animals show that tars from cigarette smoke do cause cancer.Medical authorities do not hesitate to say that smoking causes lung cancer. The U.S. Surgeon General states that cigarette smoking is ôthe largest avoidable cause of death and disability in the United States.ö The evidence for causation is overwhelming---but it is not as strong as the evidence provided by well-designed experiments.
Try Self-Check 20 Review the content from lessons Transforming Relationships and Cautions about Correlation and Regression and take Multiple Choice 7. |
|||||||||||||||||||||||||||||||||